The longest-established important application of
statistical techniques to linguistic problems is stylometry, a method of
resolving disputed authorship (usually in a literary context, occasionally for
forensic purposes) by finding statistical properties of text that are
characteristic of individual writers, such as mean word or sentence length, or
frequencies of particular words (see e.g. Morton 1978).
Such a technique was proposed by Augustus De Morgan
in 1851 in connexion with the authorship of the Pauline Epistles; concrete
investigations, using methods of greater or lesser statistical sophistication,
have been carried out by many scholars, beginning with T.C. Mendenhall in
1887. The mathematical foundations of the topic were studied by Gustav Herdan
(e.g. Herdan 1966), who showed for instance that the right way to measure
vocabulary richness (type/token ratios), avoiding dependence on size of
sample, is to divide log(types) by log(tokens). A.Q. Morton's stylometric
demonstration that no more than five Epistles can be attributed to Paul
attracted considerable attention in 1963, from a public intrigued by the idea
that a computer (seen at that time as an obscure scientific instrument) might
yield findings of religious significance. However, this work remains
controversial. Other leading investigations were carried out by George Udny
Yule on De Imitatione Christi, by Alvar Ellegård on the Letters of
Junius, and by Frederick Mosteller and David Wallace on the Federalist Papers.
More recently, Douglas Biber (e.g. Biber 1995) has
moved stylometry away from concern with individual authorship puzzles to shed
light on broader considerations of historical evolution of style, and on genre
differences in English and other languages, by means of factor analysis
applied to grammatical features of texts.
A very different area is the use of numerical
measures of resemblance between pairs of languages in order to establish the
shape of the Stammbaum (family tree) of relationships among languages of a
family. Early work (e.g. by Ernst Förstemann in 1852 and Jan Czekanowski
in 1927) used phonological and grammatical properties to measure resemblance;
but writers such as Morris Swadesh in the 1950s considered mainly the
proportions of words for "core concepts" which remained cognate in
pairs of descendant languages. The terms lexicostatistics and
glottochronology are both used to describe such research (on which see
e.g. Embleton 1986), although "glottochronology" is often reserved
for work which assumes a constant rate of vocabulary replacement (an
assumption regarded by many as unwarranted), and which thereby yields absolute
dates for language-separation events. This type of research has recently been
placed on a sounder theoretical footing by drawing on the axioms of biological
cladistics. Don Ringe and others have used cladistic techniques to
investigate relationships between the main branches of the Indo-European
language family; in many respects their work confirms traditional views, but
it gives unexpected results for the Germanic branch (which includes English).
Johanna Nichols (1992) has used a different biologically-inspired approach,
applying cluster-analysis techniques adapted from population genetics to
statistics concerning the geographical incidence of grammatical features, in
order to investigate early, large-scale human migration patterns. She claims
that language statistics demonstrate that the Americas must have been
colonized much earlier than was previously believed.
A third statistical approach to language was based
on a generalization about word frequencies, stated by J.B. Estoup as early as
1916, but later publicized by George Kingsley Zipf, with whose name it is
nowadays usually associated. Zipf's Law, 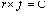 , says that, in a long text, the rank of a word (commonest
word = 1, second commonest = 2, etc.), multiplied by the word's frequency,
will give roughly the same figure for all words. (Zipf also stated a second
law, which asserted a log-linear relationship between word frequencies, and
numbers of words sharing a particular frequency; he believed this to be a
corollary of his first law, but that is incorrect - mathematically the two
generalizations are independent of one another.) Zipf explained his
"law" in terms of a Principle of Least Effort, on which he based a
wide-ranging (and in some respects controversial) theory of human
behaviour.
, says that, in a long text, the rank of a word (commonest
word = 1, second commonest = 2, etc.), multiplied by the word's frequency,
will give roughly the same figure for all words. (Zipf also stated a second
law, which asserted a log-linear relationship between word frequencies, and
numbers of words sharing a particular frequency; he believed this to be a
corollary of his first law, but that is incorrect - mathematically the two
generalizations are independent of one another.) Zipf explained his
"law" in terms of a Principle of Least Effort, on which he based a
wide-ranging (and in some respects controversial) theory of human
behaviour.
Although called a "law", Zipf's finding
is an approximation only; commonly it is quite inaccurate for the highest and
lowest ranks, though reasonably correct in the middle ranges. In the 1950s,
Benoît Mandelbrot modified Zipf's Law to make it more empirically
adequate, setting this work in the context of a proposed new discipline of
"macrolinguistics", which was intended to bear the same relation to
grammar (or "microlinguistics") as thermodynamics bears to the
mechanics of individual gas molecules (Apostel et al. 1957). It is debatable
whether Zipf's Law tells us anything surprising or deep about the nature of
language or linguistic behaviour; George Miller argued in 1957 that the
"law" was virtually a statistical necessity. But, as Christopher
Manning and Hinrich Schütze have put it, Zipf's Law does remain a good
way to summarize the insight that "what makes frequency-based approaches
to language hard is that almost all words are rare".
In the 1960s and 1970s, numerical techniques fell
out of favour in linguistics. (William Labov's pioneering work on the
statistical rules governing social variation in language was carried out in
conscious opposition to prevailing orthodoxies.) The subsequent revival of
numerical approaches was due partly to a swing of intellectual fashion, but
important roles were also played by two concrete developments: the creation of
large samples or "corpora" of language in computer-readable form,
the first of which was published as early as 1964, and the greatly increased
accessibility of computers from the early 1980s. These factors made it easy
for linguists to examine statistical properties of language which it would
previously have been impractical to study.
Some corpus-based statistical work is an extension
of traditional descriptive linguistics. Here are three examples (among many
which could have been quoted). Our understanding of lexical differences
between British and American English has been enlarged by Hofland &
Johansson's publication of comprehensive tables of statistically significant
differences between the frequencies of words in the two dialects (Hofland
& Johansson 1982): these show, for instance, that masculine words such as
he, boy, man, words referring to military or violent concepts, but also words
from the religious domain, are significantly more frequent in American
English, while feminine words, hedging words such as but and possible, words
referring to family relationships, and the word disarmament, are significantly
commoner in British English. (At least, this was true forty years ago, when
the corpora analysed by Hofland & Johansson were compiled.) Harald Baayen
has demonstrated that objective statistical methods for measuring the relative
productivity of various word-derivation processes in English give results
which sometimes contradict both linguists' intuitions and non-statistical
linguistic theory. Sampson (2001, ch. 5) finds that the grammatical
complexity of speech seems to increase with age of the speaker, not just in
childhood but through middle and old age, contrary to what might be predicted
from "critical period" theories of language learning.
Alongside investigations with purely scholarly
goals, corpus-based statistical techniques have also come into play as an
alternative to rule-based techniques in language engineering. (For a survey,
see Manning & Schütze (1999).) A central function in many automatic
language processing systems is parsing, i.e. grammatical analysis. The
classic approach to automatic parsing of natural language treated the task as
essentially similar to that of "compiling" computer programs written
in a formal language, with a parser being derived from a generative grammar
defining the class of legal inputs. However, this approach encounters
difficulties if natural languages fail in practice to obey rigorous
grammatical rules, or if (as is often the case) the rules allow very large
numbers of alternative parses for sentences of only moderate length.
Accordingly, the 1990s saw an upsurge of interest in parsing techniques based
on language models which include statistical information distilled from
corpora. For instance, probabilities may be assigned in various ways to the
alternative rewrites allowed by a phrase-structure grammar; or the language
model may altogether eschew the concept "ill-formed structure" (and
"ill-formed string") and assign numerical scores to all possible
ways of drawing a labelled tree over any word-string, with the correct parse
scoring higher than alternatives in the case of those strings which are good
sentences. Various (deterministic or stochastic) optimizing techniques are
then used to locate the best-scoring analysis available for an input; and
statistical optimizing techniques may also be used to induce the probabilistic
grammar or language model automatically from data, which may take the form of
a "treebank" - a language sample in which sentences have been
equipped with their correct parse trees.
These approaches have brought computational
linguistics into a closer relationship with speech research, where it has been
recognized since the 1970s that the messiness and unpredictability of speech
signals make probabilistic optimizing techniques centrally important for
automatic speech recognition. In speech recognition (see e.g. Jelinek 1997),
one is given a physical speech signal and aims to locate the sequence of words
which is most probable, given that signal. In other words, one wishes to
maximize a conditional probability p(w|s); and empirical data give one
estimates for the converse conditional probabilities p(s|w), that is the
probabilities of particular signals, given various word-sequences. Various
useful language-engineering applications can be cast in similar terms. By
Bayes's Theorem, 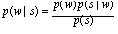 ; so, in order to
calculate the quantity we are interested in, we need to be able to estimate
the p(w)'s, the prior probabilities of various word sequences in the language.
Speech researchers commonly estimate p(w)'s using crude "n-gram"
(usually bigram or trigram) language models, which estimate the probability of
a long word-sequence simply from the frequencies of the overlapping pairs or
triples of words comprised in the sequence, ignoring its linguistic structure.
Linguists' hopes that grammar could be deployed to improve on the performance
of n-gram models have not so far borne fruit. Conversely, simple
collocation-based techniques have begun to be used for tasks that were
previously assumed to depend crucially on subtle linguistic analysis: for
instance, there have been experiments in automatic development of machine
translation systems by extracting parallel collocations from large bodies of
bilingual text, such as the Canadian Hansard. In general, one consequence of
the introduction of statistical techniques in natural language processing has
been a shift towards simpler grammar formalisms or language models than those
which were popular in linguistics previously.
; so, in order to
calculate the quantity we are interested in, we need to be able to estimate
the p(w)'s, the prior probabilities of various word sequences in the language.
Speech researchers commonly estimate p(w)'s using crude "n-gram"
(usually bigram or trigram) language models, which estimate the probability of
a long word-sequence simply from the frequencies of the overlapping pairs or
triples of words comprised in the sequence, ignoring its linguistic structure.
Linguists' hopes that grammar could be deployed to improve on the performance
of n-gram models have not so far borne fruit. Conversely, simple
collocation-based techniques have begun to be used for tasks that were
previously assumed to depend crucially on subtle linguistic analysis: for
instance, there have been experiments in automatic development of machine
translation systems by extracting parallel collocations from large bodies of
bilingual text, such as the Canadian Hansard. In general, one consequence of
the introduction of statistical techniques in natural language processing has
been a shift towards simpler grammar formalisms or language models than those
which were popular in linguistics previously.
Back to Mathematical Linguistics Area